DNS-Filterung, Datenschutz und Betriebspraxis – ausgewogen zwischen Technik und Umsetzung
Inhalt
Einordnung und Zielsetzung
Ich nutze Pi-hole nicht als „Werbeblocker“, sondern als zentralen DNS-Resolver mit Filterfunktion im lokalen Netzwerk. Ziel ist es, DNS-basierte Metadatenflüsse transparenter zu machen, Tracking- und Werbe-Domains frühzeitig zu blockieren und die Namensauflösung als Architekturbaustein bewusst zu kontrollieren.
- Kontrolle über DNS-Auflösung statt Blackbox-Resolver
- Transparenz über Domain-Anfragen
- Reduktion von Tracking- und Werbedomains
- Frühwarnung bei auffälligen DNS-Mustern
- Praxisnutzen ohne Client-Plugins
Warum DNS dabei der zentrale Hebel ist
DNS (Domain Name System) übersetzt Domainnamen in IP-Adressen. Unabhängig davon, ob die spätere Verbindung über HTTPS verschlüsselt ist, ist DNS meist die erste technisch sichtbare Stufe, auf der erkennbar wird, welche Dienste kontaktiert werden sollen. Damit ist DNS eine hochwertige Metadatenquelle und gleichzeitig ein wirksamer Ansatzpunkt für eine netzwerkweite Policy.
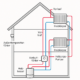
Architektur: Wo Pi-hole sitzt
Pi-hole wird so betrieben, dass alle Geräte im Netzwerk es als DNS-Server nutzen:
Clients → Pi-hole → Upstream-DNS (Forwarder oder Unbound) → Internet-DNS
Der Router bleibt Gateway und Firewall, Pi-hole ergänzt diese Architektur als zentraler Resolver.
- Resolver-Frontend für alle Clients
- Filterinstanz (Blocklisten, Regeln)
- Transparenzpunkt (Dashboard, Query-Log)
- Policy-Enforcement auf Domain-Ebene
DNS-Filterung technisch: Anfragefluss, Antwortcodes, Grenzen
- DNS-Anfrage des Clients an Pi-hole
- Abgleich gegen Blocklisten und lokale Regeln
- Bei Treffer: Antwort mit
NXDOMAIN oder Sinkhole-IP
- Bei Freigabe: Weiterleitung an den Upstream-DNS
Pi-hole blockiert Domains, keine Inhalte. Es findet keine Deep Packet Inspection statt.
Upstream-Strategie: Forwarder oder rekursiver Resolver (Unbound)
Forwarder
Pi-hole → externer DNS
- einfach und performant
- DNS-Metadaten liegen beim Anbieter
Unbound
Pi-hole → Unbound → Root → TLD → Authoritative DNS
- eigene Rekursion
- keine zentrale externe DNS-Sammelstelle
- mehr Kontrolle, etwas mehr Betriebsaufwand
Datenschutz in der Praxis: Privacy-Level, Logging, Aufbewahrung
DNS-Logs sind personenbezogene Metadaten, sobald Geräte zuordenbar sind. Pi-hole erlaubt eine differenzierte Steuerung.
- Privacy-Level bewusst wählen
- Aufbewahrungsdauer begrenzen
- Detailliertes Logging nur temporär
Einrichtung: So wird Pi-hole im Netz wirksam
- DNS-Verteilung über Router/DHCP
- optional: Pi-hole als DHCP-Server
- keinen externen „zweiten DNS“ eintragen
- Redundanz besser mit zweitem Pi-hole
Blocklisten: bewusst reduziert, fachlich begründet
Bei der Auswahl der Blocklisten folge ich konsequent dem Prinzip „weniger ist mehr“. Ziel ist keine maximale Blockquote, sondern eine stabile, nachvollziehbare DNS-Filterung mit möglichst wenigen Fehlblockaden.
Ich nutze daher nur wenige, etablierte Quellen mit klarer Ausrichtung:
- Große kuratierte Aggregationsliste
Diese deckt den überwiegenden Teil bekannter Tracking-, Werbe- und Analyse-Domains ab. Der Vorteil liegt in der regelmäßigen Pflege, Dublettenbereinigung und einer ausgewogenen Balance zwischen Abdeckung und Stabilität.
- DNS-spezifische Filterliste
Ergänzend setze ich eine Liste ein, die speziell für DNS-Blocking optimiert ist. Sie berücksichtigt typische DNS-Strukturen (Subdomains, Wildcards) und ist nicht einfach ein umgebautes Browser-Filterset.
- Abuse- und Malware-Feed
Diese Quelle fokussiert sich auf bekannte schädliche Infrastrukturen wie Malware-, Phishing- oder Command-and-Control-Domains. Sie dient weniger der Werbeblockade als der frühen Unterbindung klar unerwünschter Kommunikation.
Zusätzliche Blocklisten würden in der Praxis meist nur noch geringe Zugewinne bringen, erhöhen jedoch:
- die Anzahl von False Positives
- den Pflege- und Analyseaufwand
- die Intransparenz bei Fehlfunktionen
Durch die bewusste Beschränkung bleibt das DNS-Verhalten erklärbar: Wenn etwas blockiert wird, ist auch nachvollziehbar warum. Das ist aus Betriebssicht wichtiger als eine möglichst hohe Blockzahl.
Betrieb auf der Synology NAS im Docker-Umfeld
Pi-hole läuft bei mir nicht auf dedizierter Hardware, sondern als Container auf einer Synology NAS. Diese Entscheidung ist bewusst getroffen und folgt denselben Prinzipien wie die reduzierte Blocklistenstrategie: Stabilität, Wartbarkeit und klare Zuständigkeiten.
Die NAS ist ohnehin als dauerhaft betriebene Infrastrukturkomponente ausgelegt und in meinem Umfeld 24/7 verfügbar. Sie übernimmt bereits zentrale Aufgaben wie Datenspeicherung, Backup und weitere Netzwerkdienste. Pi-hole fügt sich hier als zusätzlicher, logisch abgegrenzter Dienst ein – ohne zusätzliche Hardware, Netzteile oder separate Systeme.
Der Betrieb im Docker-Umfeld bietet dabei mehrere technische Vorteile:
- Klare Trennung zwischen Anwendung (Pi-hole) und Host-System
- Reproduzierbare Konfiguration über persistente Volumes und Container-Definitionen
- Einfache Updates ohne Eingriff in das NAS-Basissystem
- Saubere Rollback-Möglichkeiten bei Problemen
- Integration in bestehende Backup- und Monitoring-Konzepte der NAS
Aus Sicht der Verfügbarkeit ist diese Architektur sinnvoll: Die NAS ist bereits auf Dauerbetrieb ausgelegt, überwacht und abgesichert. Ein zusätzlicher Einplatinenrechner oder separater Mini-Server würde die Anzahl potenzieller Fehlerquellen erhöhen, ohne einen echten Mehrwert zu liefern.
Auch der Ressourcenbedarf von Pi-hole spricht für diesen Ansatz. DNS-Auflösung ist technisch leichtgewichtig: CPU-Last und Speicherbedarf sind gering, selbst bei mehreren hunderttausend geblockten Domains. Im Docker-Betrieb beansprucht Pi-hole nur einen sehr kleinen, klar begrenzten Teil der verfügbaren Systemressourcen.
Pi-hole ist damit kein leistungskritischer Dienst, sondern ein stabiler Basisdienst, der zuverlässig im Hintergrund arbeitet. Der Container-Betrieb unterstützt genau diesen Charakter: isoliert, ressourcenschonend und kontrollierbar, ohne die übrigen Funktionen der NAS zu beeinträchtigen.
Grenzen und Umgehungen
- Client-DoH/DoT kann DNS-Filter umgehen
- VPNs bringen eigene Resolver mit
- IP-basierte Ziele ohne DNS bleiben unbeeinflusst
Fazit
Pi-hole ist in meiner Netzarchitektur ein strategischer Kontrollpunkt. Der Nutzen entsteht nicht durch maximales Blocken, sondern durch saubere Architektur, bewusste Upstream-Wahl, kontrolliertes Logging und gepflegte Regeln.
Damit ist Pi-hole keine Spielerei, sondern solide, nachvollziehbare Netztechnik.


 Eric Beuchel
Eric Beuchel