Beschreibung des Scripts
Dieses Python-Script ist ein PDF-OCR-Tool, das gescannte PDF-Dokumente automatisiert mit Tesseract OCR durchsucht und durchsuchbaren Text erzeugt. Es überprüft zunächst, ob eine PDF-Datei bereits eine durchsuchbare Textschicht besitzt. Falls nicht, wird jede Seite als Bild extrahiert, automatisch gedreht (um z.B. falsch orientierte Seiten gerade auszurichten) und per Tesseract OCR in ein neues PDF mit Textschicht umgewandelt.
Hauptfunktionen:
-
Ghostscript-Suche: Das Script findet automatisch den Ghostscript-Pfad (zur PDF/A-Konvertierung).
-
Textschicht-Erkennung: Mit Ghostscript wird geprüft, ob die PDF schon Text enthält (OCR dann nicht nötig).
-
OCR mit Tesseract: Jede PDF-Seite wird als Bild geladen, automatisch rotiert (mittels Tesseract’s OSD) und OCR durchgeführt.
-
Rotation: Falsch ausgerichtete Seiten werden vor OCR korrigiert.
-
PDF/A-Konvertierung: Optional kann das Ergebnis in ein PDF/A-konformes Format konvertiert werden (für Langzeitarchivierung).
-
Dateimanagement: Original-PDFs werden in einen Unterordner „erledigt“ verschoben, die OCR-PDFs in „mit_OCR“.
-
Logging: Vorgänge und Fehler werden in einer CSV-Datei protokolliert.
-
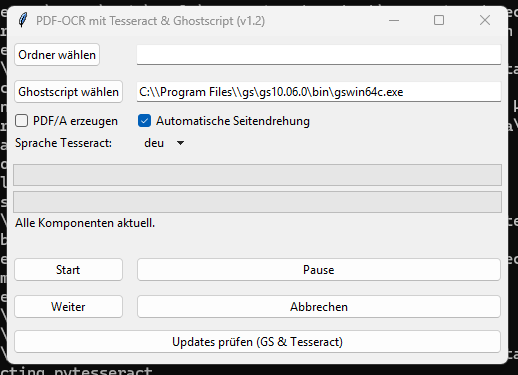
GUI: Einfaches Tkinter-Interface zur Auswahl des Quellordners, Ghostscript-Pfads, Spracheinstellungen (Deutsch, Englisch, Deutsch+Englisch), PDF/A-Option und Steuerung (Start, Pause, Fortsetzen, Abbrechen).

 pixabay
pixabay