Script PDF – OCR Tool
Ein PDF-OCR-Tool dient im archivischen Umfeld der automatisierten Texterkennung und Qualitätssicherung von PDF-Dokumenten. Ziel ist die Umwandlung von gescannten oder bildbasierten Seiten in durchsuchbare, maschinenlesbare Texte als Teil eines strukturierten Archiv-Workflows.
Diese Seite dokumentiert sachlich Aufgabenstellung, technische Arbeitsweise des Tools und erläutert, warum OCR im Archiv eine zentrale Rolle spielt – unabhängig von konkreten Programmen oder kurzfristigen Komfortgewinnen.
OCR macht aus einem visuellen Dokument ein inhaltlich erschließbares Archivobjekt. Ohne OCR bleibt ein PDF technisch gesehen ein Bild – mit stark eingeschränkter Nutzbarkeit.
Inhaltsverzeichnis
- Aufgabenstellung
- Warum OCR im Archiv notwendig ist
- Technische Grundlagen: Was ist OCR?
- Beschreibung des PDF-OCR-Tools
- Tool-Architektur und Arbeitsweise
- Eingesetzte Programme (Goodie)
- Qualität, Fehlerquellen, Grenzen
- Praxis-Checkliste für Archiv-OCR
- Archivischer Hinweis
Aufgabenstellung
Das PDF-OCR-Tool wird eingesetzt, um gescannte oder bildbasierte PDF-Dokumente automatisiert auf eine vorhandene Textschicht zu prüfen und diese bei Bedarf zu erzeugen. Ziel ist eine einheitliche, durchsuchbare und langfristig nutzbare Dokumentbasis.
- Erkennung vorhandener Textschichten
- OCR-Verarbeitung bildbasierter Seiten
- Erzeugung einer unsichtbaren Textschicht
- Optionale PDF/A-Erstellung für die Langzeitarchivierung
- Nachvollziehbare Protokollierung der Verarbeitung
Warum OCR im Archiv notwendig ist
Ein Archiv dient nicht nur der Aufbewahrung, sondern der langfristigen Nutzbarkeit von Informationen. Dokumente sollen auch Jahre oder Jahrzehnte später auffindbar, überprüfbar und einordenbar sein.
Ein gescanntes PDF ohne Textschicht ist in diesem Sinne ein unvollständiges Archivobjekt. Der Inhalt ist sichtbar, aber technisch nicht erschlossen.
- Ohne OCR keine Volltextsuche
- Ohne OCR keine inhaltliche Erschließung
- Ohne OCR eingeschränkte Weiterverarbeitung
OCR schafft eine zweite Ebene: Neben dem visuellen Abbild existiert eine maschinenlesbare Textrepräsentation. Erst dadurch wird ein Dokument inhaltlich nutzbar.
Ein Dokument ohne Textschicht ist archiviert, aber nicht erschlossen.
Gerade in digitalen Archiven mit vielen tausend Dokumenten ist OCR Voraussetzung für:
- zuverlässige Volltextsuche
- thematische Zuordnung und Klassifikation
- inhaltliche Nachvollziehbarkeit bei späterer Nutzung
- automatisierte Weiterverarbeitung (Indexierung, Regeln)
OCR ist damit keine Komfortfunktion, sondern ein strukturelles Element moderner Archivarbeit.
Technische Grundlagen: Was ist OCR?
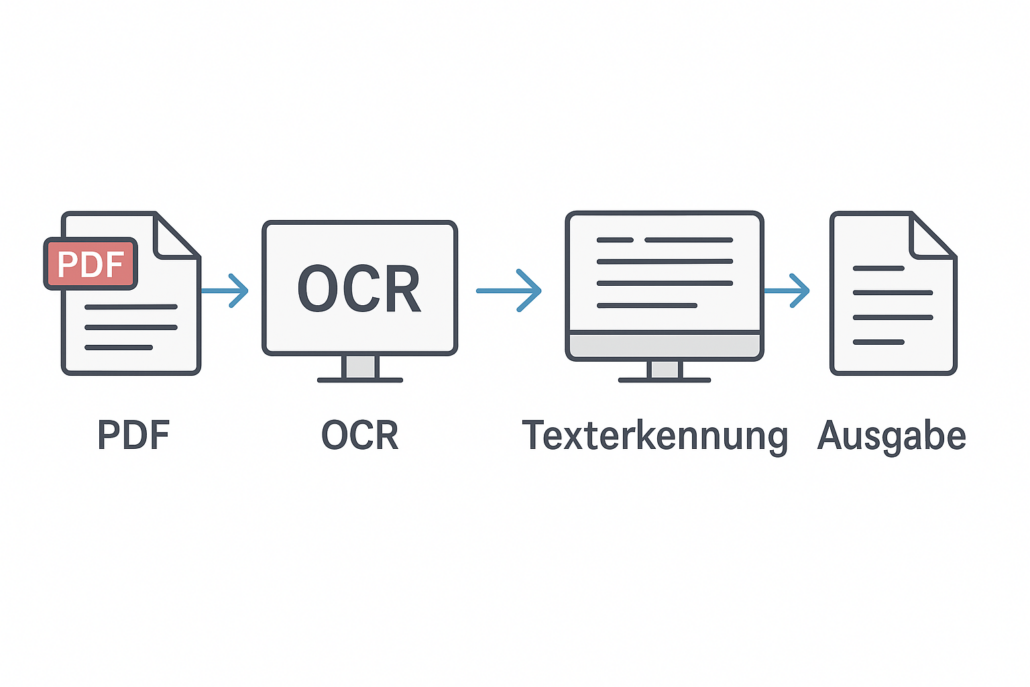
OCR (Optical Character Recognition) bezeichnet die automatische Erkennung von Text in Bildern oder gescannten Dokumenten. Die visuelle Information wird in maschinenlesbaren Text überführt.
Für Archive bedeutet dies die Trennung von Darstellung (Bild) und Inhalt (Text).
Beschreibung des PDF-OCR-Tools
Das Tool prüft PDF-Dateien auf vorhandene Textschichten. Fehlt eine nutzbare Textrepräsentation, wird eine OCR-Verarbeitung durchgeführt und die Textschicht ergänzt.
- Analyse bestehender Textschichten
- Seitenweise OCR bei Bedarf
- Erhalt des originalen Seitenbilds
- Erzeugung einer durchsuchbaren PDF-Datei
Tool-Architektur und Arbeitsweise
Der OCR-Workflow ist modular aufgebaut und trennt Analyse, Erkennung und Archivierungsschritte sauber voneinander.
- PDF-Analyse
- Bildextraktion
- OCR-Erkennung
- Zusammenführung
- Archivkonforme Ablage
Eingesetzte Programme (Goodie)
Zur Umsetzung des OCR-Workflows werden etablierte Werkzeuge eingesetzt, die sich langfristig bewährt haben:
- Ghostscript zur PDF-Analyse und PDF/A-Erstellung
- Tesseract OCR als OCR-Engine
- PDF24 OCR für Vergleichs- und Ergänzungsläufe
- ExifTool zur Metadatenprüfung und -bereinigung
Die Programme sind austauschbar. Entscheidend ist der archivische Anspruch, nicht das einzelne Werkzeug.
Qualität, Fehlerquellen, Grenzen
OCR-Ergebnisse sind abhängig von der Qualität der Vorlage. Unscharfe Scans, ungewöhnliche Schriftarten oder komplexe Layouts führen zu schlechteren Ergebnissen.
OCR erhöht die Nutzbarkeit eines Dokuments, ersetzt aber nicht dessen inhaltliche oder rechtliche Prüfung.
Praxis-Checkliste für Archiv-OCR
- Scans in ausreichender Qualität erstellen
- Vorhandene Textschichten prüfen
- OCR-Läufe dokumentieren
- PDF/A für Langzeitarchivierung erwägen
- Ergebnisse stichprobenartig kontrollieren
 pixabay
pixabay